 Pat Flynn
Pat Flynn
Imagine this:
You own a brick and mortar business in your hometown, and business is good.
One morning you wake up, take a shower, put on your work clothes and grab a coffee and a blueberry muffin on your way out, just like every other day. You drive towards your store and as you pull up, you notice something weird: all of the windows are boarded up.
That’s strange.
You scurry to the door, insert the key and push—but the door doesn’t budge.
Hmm . . .
Looking more closely, you see that the door is actually welded shut.
You run to the back entrance. Same deal.
There is no way anybody is getting in, at least for the time being.
Suddenly, it’s 9:00am and cars start to roll into the parking lot. A few coast by only to notice your ‘abandoned’ store and they drive away. Others stop in front of you on the curb and ask you what’s going on or when you’ll be open for business again, but unfortunately you don’t have an answer for them.
On Monday, February 25th, this happened to me—not with a brick and mortar store, but with my websites—almost all of them—including this blog.
They were down for an entire week, which in the online world feels like an eternity.
This is a detailed account of what happened, lessons learned and strategies for dealing with situations like this for the future.
Story, Begin
On Monday, February 25, I woke up at 6am and drove to the Solana Beach train station where I was going to meet my videographer to shoot some footage for my upcoming book, Let Go. You’ll hear more about this project very soon.
Around 9am, while filming on the train I checked my Twitter stream on my phone and noticed 2 or 3 messages from people saying that Smart Passive Income was loading incredibly slow. I checked on my phone’s browser and it was taking between 10 to 15 seconds to load, but this happens sometimes. Sometimes the server is being worked on or maybe a huge amount of traffic just decided to stop by all at the same time, so I didn’t think too much of it because usually the problem solves itself after a few minutes.
Around lunch time, I checked the website again and everything seemed to be back to normal. I saw a spam comment come through and had a few seconds to delete it, but when I tried logging into the backend of my site through WordPress, the login page took two minutes to load before I was met with a 503 Service Unavailable error.
Hmm…
I checked the homepage and it was up to speed, but when I clicked a banner ad for Bluehost in my sidebar, it took two minutes to load before I was met with another 503 Service Unavailable error. The link, smartpassiveincome.com/bluehost, is a redirect link through a plugin called Pretty Link. I use Pretty Link to shorten longer links and also keep track of the number of clicks for each. I tried some other links that I knew ran through Pretty Link, and none of them were working. This meant that if someone tried to purchase something through any of my affiliate links, or even be redirected to my show notes from my podcast, it would come up as an error.
Not good.
I decided to log into WordPress to see if something was up with Pretty Link, but oh yeah—I couldn’t access the log in page.
Something was going on.
We had some more videos to shoot so there was nothing I could do at the moment except wait and hope it was just a temporary glitch. I was annoyed but I had to focus on filming first. At least the front end of the site was sort of working…for now.
Around 6pm I finally got home and checked the blog.
Nothing.
It wasn’t loading at all. It wasn’t even trying to load, the browser just read “server unavailable.”
I logged into my server to open up a support ticket, but I decided to call instead. In a minute, I was on the phone with a technician.
I kept asking myself: Why didn’t I just call earlier!?
(Tip: have the number for support entered into your phone so you can call right away if something happens to your site.)
The technician on the phone told me that earlier that morning there was a huge influx of activity on the site, mainly through PHP processes, that was the root of the issues that was happening on the site. They started a ticket to get their support team on it right away, which I was thankful for.
Within that conversation, I was shown this graph:
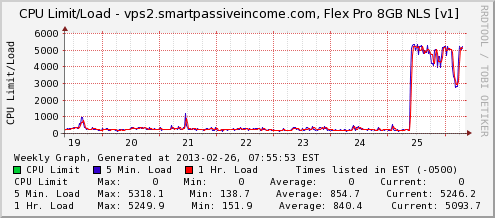
A max load of 5318.1 (whatever that means) for hours, non-stop meant that something paranormal was definitely happening. I still had no clue what was going on or how to fix it, so I just had to hope that the tech team could figure it out.
They asked me if I did anything to the site at that time—maybe installed a particular plugin or changed something that could have caused this kind of load starting on the 25th, but I hadn’t touched anything since the 22nd, so it was definitely something external.
It was getting late and I had woken up earlier than usual that day. I was tired and I just hoped that everything would be okay when I woke up the next morning.
The Next Day
I woke up and saw this message from the support team:
“I have not been successful in determining what exactly is causing the high load. I am moving this over to the escalated department for review.”
Breath Pat…breath.
Okay, cool. The “escalated department”. Surely they can help.
It was then when I noticed a number of emails from people saying that the map that they downloaded from my map generator website was not loading anymore. I went to createacliakablemap.com and surely enough, it wasn’t coming up at all.
Then, I checked securityguardtraininghq.com, my most successful niche site that was averaging $120+ a day. It was down too.
Every website that I was hosting on that dedicated server was down.
I reported this back to the “escalated department” who came back and said that my W3TC plugin (W3 Total Cache) was not configured correctly. They blocked people from coming to the site so they could work on re-configuring the plugin, which didn’t matter because nobody could come to the site anyway.
After a couple of hours, support finally got back to me:
Hello, the load is hovering around 17, which isn’t great. W3TC is now working but the majority of the load is now coming from mysql. I’m by no means a expert when it comes to sql, but it looks as the query is trying to select columns which don’t exist.
COUNT(wp_comments.comment_post_ID
There is no comment_post_ID in the wp_comments table.
Again, I had no idea what this meant, but the front end of the site came back up, but something was very strange: no posts were showing up. All I could see was the theme and the sidebar, but there was no content on the site. I still couldn’t log in, and I think I was turning red at this point.
Five minutes later, the server stopped working again.
I went back to support and they suggested that we try reverting back to an earlier date before the massive CPU load started. After 3 hours, the site was restored to what it was on February 16th. The site was back up and I could actually log in again! The site was still extremely slow, and I had lost two posts that I had written between the 16th and the 26th.
Well, after 30 minutes—the server stopped working again. 🙁
What. A. Tease.
I had to bring in outside help.
This is when I reached out to my buddy Matthew Horne from DIY WP Blog, who I had hired in the past to help me optimize the SPI blog and my security guard site for speed.
Immediately, he went to work and came to the quick conclusion, based on everything I told him and looking at the data server-side, that my site was being attacked.
A DoS (denial-of-service) attack, to be exact.
A DoS attack is (I had to look this up) an attempt to make a machine (server) unavailable to its intended users. This is done by saturating a machine with external requests, so much so that it cannot respond to legitimate traffic, or responds so slowly that the server essentially becomes unavailable.
Knowing that at this point I was probably going to be writing a long post about exactly what happened for you all, I asked Matthew how he came to this conclusion. He sent me an error log from my server and this is what he said:
You can view the repeated crash and restart of mysql, the database was hit so hard it did not have time to shut down normally and each time it restarted it was proceeded almost immediately by another crash. The error log for the SPI contains approximately 180,000 errors in regards to mysql. The error is as follows:
WordPress database error MySQL server has gone away for query INSERT (additional information here
varies due to the different tables being requested)
This occurs when the database was unable to complete a process or it was closed before it completed.
Think of it like this: when you go to some train stations, you sometimes see those gates where you have to put your card or ticket through to let you in. So when you request a site, it’s like your putting your ticket in, getting processed and the gate opens. You’re in and doing your thing.
Then imagine thousands of people suddenly showing up all trying to get through the gate at the same time, all placing their tickets in to be processed. The server can only handle so many requests at a time and eventually it crashes and reboots, only to find that that queue is still there and even bigger. Normal traffic cant get in because there is an enormous queue in front of them.
Someone or something was sending hundreds, if not, thousands of requests to SPI, which is causing your server to overload and deny traffic to all of your websites.
A few of things were going through my head:
- So, I wasn’t hacked. Originally I thought I was hacked, but Matthew assured me that security wasn’t the issue. A DoS attack doesn’t require any sort of infiltration in order to happen.
- Why me? Why was I getting attacked? It wasn’t fair, but things like there are hardly ever. Then, I remembered hearing about DoS attacks on major sites, and I knew that it was probably just a part of having a high-profile site.
- So what now? Where do I go from here. How do we fix this issue?
- What can I do, or what could I have done to prevent this? I explore this later in this post.
- Why wasn’t I getting help from my server company? This is what bugged me the most. My server, Servint, had always been great. Always—up until this incident. They were quick to answer support emails and calls (and still were), yet, I still felt like nobody on the other end truly cared about my situation enough to help me find a solution. I kept getting data, but I wanted results.
Unfortunately, with a site like SPI and the other sites that I own, I felt that even though they dropped the ball just this once, it was enough to convince me to look for a better solution. Another host.
I talked this over with Matthew and he said that a migration at this point was probably a good idea and would most likely solve the problem since I’d have a new IP address. It’s not the best solution, but at this point I was ready to move hosts and also put SPI on its own segmented dedicated server. In other words, SPI would be on its own server, and the other sites I own could be hosted on another. This way if SPI is attacked again or something happens to the server, my other sites aren’t affected (and vice versa).
Time to Migrate
Migrations are a pain and the way it works can be confusing for a first timer. I had done this before when SPI outgrew shared hosting, so hopefully this extremely basic explanation helps newbies:
A website has a domain name (the web address), and a server (where the data for that website is served to those who visit that web address).
The domain name has information behind it that points to a specific server.
Sometimes, when you create a website, the domain and the server are with the same company (like if you purchase domain and hosting through BlueHost. Other times, your domain might be with a registrar such as GoDaddy, and your server could be at another company. [Full Disclosure: As an affiliate, I receive compensation if you purchase through this link.]
Either way, before you migrate, you have yourwebsite.com pointing to some original server.
When you migrate, what you do is actually duplicate your site on a brand new server and then tell your domain registrar to point to the new server instead of the old one by switching nameservers.
After migration, your old server is actually still there, but when you update your website it makes changes on the new server, not the old one.
For me, the first step was finding a new hosting company, and then duplicating what I have on my old server onto the new one.
Through recommendations from some of my close friends, I ended up going with Storm On Demand and I purchased 2 dedicated servers, one to serve Smart Passive Income, and another to serve most of my other projects, including Security Guard Training Headquarters and Create a Clickable Map. I still have shared hosting with Bluehost for some of my smaller and experimental niche sites, as well as Green Exam Academy.
At this point, with the success of the blog, there’s no reason for it not to be on its own beefed up server.
Once the new servers were up and running (which took a few hours), it was time to actually move the site over. “Luckily”, Storm On Demand (SOD) offered to help me migrate the site over for free, so I gave them access to my old server, and they began.
Halfway through, I realized that they were migrating the February 16th version of the site. They said I could pause the process, restore back to a February 27th version of the site that was available, and then restart.
So, I had to go back to Servint, tell them to restore back to what it was. This took another few hours to complete.
Then, I went back to SOD and told them to resume.
After another few hours, everything was ready to go but when Matthew checked the backup file, it seemed to be missing a few important components. Namely my wp-content folder. This meant that the backup was fragmented when it came over, probably because of the pause and restart during the middle of it.
Whoops.
Delete.
Start over.
We tried again, but after about 6 hours, the transfer failed.
Let’s try this again.
After a few more hours, the transfer failed again!
We couldn’t figure out why the transfer kept failing. It could have been because there was a lot of data to transfer over, and apparently Matt discovered an error log that was over 65gb in size due to the DoS attack, which we cleaned out.
During the SPI migration troubles, I had setup another support ticket with SOD to transfer Security Guard Training Headquarters and Create a Clickable Map to the other new server, which went smoothly. Those sites were finally back up by March 1st.
Then, it was time to fly from San Francisco to Portland.
Just When I Thought It Couldn’t Get Any Worse
At this point, with the cPanel to cPanel transfer failing each time, Matthew suggested that we transfer files from one server to the other manually, in batches. Smaller file sizes, just more of them.
It was apparently going to take over a day to do this (and do this right). Since it takes time for new nameservers to propagate when changed at the registrar, I decided to change the nameserver to the new server ahead of time, just so that was taken care of already and we didn’t have to wait an additional 24 to 48 hours after transfer. It didn’t matter that I switched early because the site wasn’t loading on the old server anyway.
Or at least I thought it didn’t matter.
After about 4 hours, I started to get a few Direct Messages on Twitter and a couple of text messages that all said:
“Pat, your email address is bouncing back.”
Could this get any worse? Apparently so.
When the nameserver switched, it messed with my emails since the domain was pointing to a new IP address. It’s no wonder I didn’t get any new emails to my SPI email address for most of that day (especially when I average 200-300 emails per day).
Ugh!
I checked with Matthew: “How much longer until the transfer is over and we’re back up do you think?”
Matt replies: “We’re probably around 20% right now.”
And this was after 4 or 5 hours since we started…
Finally. Finally. Finally.
On Sunday, March 3rd, I flew back to San Diego from Portland. After touchdown, when I was allowed to turn on my phone, I checked the blog and it was still down. There were no new progress emails from Matthew yet.
It had almost been an entire week of downtime—I couldn’t believe it. I’ll get into the repercussions of my “week off” in a second.
When I got home, I quickly fell asleep and awoke early in the morning to a couple of emails from Matthew. One read:
“We’re almost there!”
And then a couple of hours later.
“It’s done! Check your browser!”
I immediately opened up my browser, typed in smartpassiveincome.com and boom—there it was, just like I had left it.
All that time and work just to get back to where I was.
Relieved doesn’t even begin to describe how I was feeling.
Finally.
Matthew was still running tests and rebooting the server from time to time as he optimized its settings, so for a few moments it would be unavailable and I’d freak out for half a second, but then it would come back up again.
I also had to re-setup Google Apps for Business to resync my email with the new server, but after I did that the email was back to normal.
And here I am now, exactly two weeks later (since this post took a little longer than expected to write) with my first post since my week from hell.
What an unbelievable learning experience this has been.
Thanks to the Downtime
There are a lot of things to think about as far as what happened (or didn’t happen) as a result of this week of downtime.
Many people, I’m sure, are interested in how much money I “lost”. It’s hard to say because sales, clicks, conversions and traffic vary each and every day, but if you take into account that on average I earn about $1600 a day (this is based on my monthly income reports—and again this isn’t perfect because some of those earnings are recurring, and like I said there are up weeks and there are down weeks) I lost, perhaps, nearly $12,000.
Now, that’s just short-term. Who knows how many people came to the site and were met with an error, people who could potentially click on affiliate links or purchase products in the future who will no longer visit the site. That’s impossible to measure, but for some I know it’s still disturbing to think about.
For me, however, the most disturbing part is just knowing that real people were coming to the site expecting something, and they were getting nothing. Whether they came from a link from another site, directed to the blog from my podcast or YouTube videos, or through a Google search—it kills me to know that people were coming to the site for something and it wasn’t there to deliver.
That’s a bad first impression. That’s a bad any impression.
I do feel like I let the community down. Even through the attack wasn’t my fault, maybe there are things I could have done better to get the site back up faster, or prevent something like this from happening.
The timing wasn’t very good either. I was on a trip to San Francisco to film some stuff and my head wasn’t all there. I then flew to Portland for an important business meeting and my head wasn’t all there. What needed to get done got done, thankfully, but I still feel terrible that I always had my website in the back of my mind.
In addition to less money earned, there was, of course, the fact that I couldn’t post up any new content. Finally, this week, we’re back to a normal posting schedule, but the podcast and blog hasn’t been updated for 2 weeks now, which is the longest in SPI history.
Matthew was a lifesaver, but of course, he comes with a fee, so there’s that too.
Besides all of the negative consequences, there were a few rays of light during this situation.
When my site went down, I had hundreds of people offer me their help. I’m talking 400 to 500 different people who emailed me or messaged me on Facebook or Twitter offering their expertise in IT or programming or development to help me get back up and running.
That is awesome. Just to know that there are SPI fans out there who are willing to help is amazing—thank you to all of you who messaged me and offered to help.
There were even some people who offered to help who obviously didn’t know what they were talking about, offering advice such as “Pat, I think you should try clearing your browser’s cache,” which I actually appreciated even more. Sure the advice was wrong, but the fact that they were trying to help meant the world to me.
And of course, now I can share this experience with you, and it makes a good story that comes with some important lessons. Before I get into prevention, there are a few things I know I did right during this whole ordeal that I’d like to share.
What I Did Right
1. I didn’t go crazy.
In situations like this it’s easy to freak out, start blaming people and get really angry, but I’ve done that before in other situations in my life and I knew that freaking out never helps—it only makes the situation worse. Once you freak out to a certain level, it’s hard to get back to the point where you can figure out how to solve the issue.
I think my Twitter followers did notice that my general feelings about the situation changed over time. Tweets went from:
“Technical issues on SPI being worked on as we speak. Thank you for your patience!”
to
“Thank you all for your patience. Still working through server issues today. This has definitely allowed ME to practice being patient.”
To this one:

To which a few people eloquently followed up with: “Kidney Stone?”
I didn’t freak out, and although things took longer than expected, the site is back up.
2. I Was Everywhere
Being Everywhere (i.e. not just on my blog, but on other platforms as well) meant that even though my blog was down, I didn’t disappear. My podcast was still up and running and was still downloaded a total of 34,136 times.
My YouTube videos still served 21,509 views and over 87,000 minutes of viewing time.
And of course, I was still able to connect with people through my Facebook Page and Twitter.
For anyone who doesn’t think it’s important to Be Everywhere and put yourself onto multiple platforms, think again.
3. I Utilized My Email List
After realizing that SPI wasn’t going to be up and running right away, I quickly sent out a broadcast email to my email list, talking about the situation and thanking people for sticking around.
It apparently made a huge impression because I received a number of replies (this was before my email started bouncing back) thanking me for the update. Many people were met with the error and didn’t know what was going on until the email came through. Others were just thankful that I took the time to keep them updated, which was pretty cool.
And when I think about this, the blog could have been wiped out and erased from existence, and I still would have been okay thanks to my email list. Worst case scenario, I could easily setup a new site somewhere else and just let my subscribers know, and I’d be back up and running in no time. Of course, I’m happy that SPI came back to life, but even if it didn’t I’d still have my email list.
This is why the email list is important—not just for pushing emails with offers and not just for driving traffic, but for staying connected—truly connect—to a group of people through an email list that you actually own.
If you don’t have an email list setup yet, now’s about time to start one.
4. I Recorded a Video
I couldn’t put up a podcast session talking about the situation, but I still had my YouTube channel!
Since I was in San Francisco and I had my videographer there with me, I told him to shoot a quick video of me explaining that I was working on the site and it would be up as soon as possible.
[Editor’s note: The video is no longer available.]
A big thanks to Greg Hickman for giving me the idea to show this to people who visited the dead server. For a while, when people would visit smartpassiveincome.com, it would redirect to this video on YouTube explaining that they could get more SPI content on the YouTube channel and podcast, linked to in the description of the video.
It’s not much, but it’s something, which is what matters.
5. I Have Insurance
For the past 8 months or so, I’ve had business insurance. This is insurance which covers various things related to my business, including server downtime do to a security breach or attack.
This is the first time I’ve filed a claim with the insurance company, so this is all still very new to me, but it’s going to be a very long and lengthy process to figure out exactly how much (if any) I will be compensated for this downtime. There is, of course, an investigation that has to happen, a lot of back and forth, paperwork, calls, and other things that I probably haven’t even thought about yet, but this just shows you that business insurance could be worth it.
Is it?
I’m not sure. Hopefully, it is. I mean, that’s why it’s there, right?
We’ll have to wait and see and I’m not completely sure about how transparent I can be about exactly what happens, but I’m sure many of you are as interested as I am. If I can share any information with you about this process, I will let you know. I’m not even sure if I can share the company’s name right now, so I will hold off on that until I get some answers.
We’ll see what happens.
Prevention
Security is extremely important when it comes to your website.
The three most obvious things you should have are:
- Strong passwords.
- An updated version of WordPress (if you are using WordPress).
- The common sense to not download anything or open emails that are suspicious.
I have an account with Sucuri, which helps with security and malware detection, which I’ve found very useful and reassuring. [Full Disclosure: As an affiliate, I receive compensation if you purchase through this link.] There are also plugins like Wordfence which do a great job of securing and monitoring one’s website as well.
Unfortunately, with something like a DoS attack, it’s much harder to prevent, which is the scary. To be honest, any site is at risk, and if someone with DoS capabilities wants to attack you, they will, which is why this happens primarily to high profile websites. The best and cheapest solution is good monitoring of things such as disk space so you can act quickly if things do start to happen.
Here is an insightful article that explains more about why DoS attacks have been happening, as well as prevention strategies and resistance.
The Internet is indeed the Wild Wild West of the 21st Century.
In addition to prevention, you’ll want to prepare just incase something does happen to our site.
Having backups for your site are a must. Some servers create backup files for you, but not all of them do—or at least at the rate at which we’d be comfortable with.
One of the most popular backup plugins used for WordPress users is BackupBuddy. With BackupBuddy, you can backup, restore and even more your WordPress site fairly easily.
I had BackupBuddy enabled and I had planned to use it to restore, but when I checked my remote server where my backup files were supposed to be saved (you can have backups saved into Dropbox, Amazon S3 or elsewhere if you’d like), the latest backup was from September 30, 2012. 🙁
Something happened where my backups stopped scheduling, or maybe they just kept failing and I didn’t know it—and perhaps whatever made this fail also made the cPanel to cPanel migration fail when I migrated servers—but who knows. Anywho—the backups are working fine now and so if something were to happen again in the future it should be a much quicker fix than before.
All I can say at this point is . . .
Phew!
Things like this happen, but you just gotta roll with the punches. Even though February was a short month to begin with and it was even shorter because of my downtime, there are still record numbers and earnings to report in February. My monthly income report is delayed a bit, but it’s coming soon.
Let Go—My Upcoming Book / Snippet
Although my sites were down and out for a while, that doesn’t mean I didn’t get any work done. The entire week I was filming and working on my upcoming book for the brand new Snippet platform called Let Go.
Let Go and the Snippet platform launches later this month, and I couldn’t be more excited!
For now, here’s a little teaser trailer that my team and I put together for you:
Click here to learn more about Let Go.
Thank you all, again, for your support, for sticking with me, and for reading this really long post! I had a lot to say, and hopefully you were able to learn something from my experience.
Cheers, and it’s great to be back! 🙂